Blog
Merci de laisser ce code dans l’état dans lequel vous aimeriez le trouver [Transcription de conférence]
Cet article est une transcription de la conférence que j’ai donnée au PHPTour 2018, parce qu’il est parfois plus pratique d’avoir une version écrite qu’une vidéo. À quelques ajustements près pour être plus lisible, le contenu de cet article reflette ce qui a été dit pendant le talk. Si vous préférez le format vidéo, il est disponible en bas de la page.
J’ai eu mon premier contact avec avec la qualité logicielle il y a maintenant une bonne dizaine d’années, avec cette citation : “Code toujours comme si la personne qui va maintenir ton code est un violent psychopathe qui sait où tu habites”.

Ça m’a bien fait rire, et je pense que c’est pour ça que je m’en souviens dix ans après. Ça m’a moins fait rire l’an dernier, quand on m’a annoncé que j’allais refiler mon code … à JP.

(J’avais hâte d’afficher cette slide sur un écran de 6 mètres de haut)
A ce moment, j’ai eu un peu peur pour ma vie. Je n’avais pas trop envie de me prendre un coup de hache, donc j’avais intérêt à filer à JP du bon code. La question que je me suis posée, ça a été …

“Qu’est ce que c’est, du bon code ?” J’ai découvert que la définition bon code dépend de qui on est, d’où on se place.
Par exemple pour certain·e·s utilisateur·rice·s, ça va être du code qui rend plus productif·ve. Pour d’autres, et on est en plein dedans avec l’actualité, ça va être du code qui respecte la vie privée. Il y a aussi des gens pour qui du bon code, c’est simplement du code qui soit accessible.

On peut aussi se placer d’un point de vue plus technique et dire que le bon code c’est du code S.O.L.I.D.
Si on se place d’un point de vue Product Owner ou d’un point de vue de CEO, ça peut être du code qui coûte peu … ou, si on est un·e bon·ne CEO, du code qui rapporte beaucoup (il y a une petite nuance entre les deux).
Bref, il y a beaucoup de façons de définir ce qu’est du bon code …

Revenons donc à mon histoire de hache.
Ce qui m’intéresse, dans mon cas, c’est finalement la “Developer Experience”, c’est à dire d’avoir du code qui permette de travailler de façon productive, dans les meilleures conditions possibles, en étant le plus confortable avec le code possible.

Mais avant de rentrer dans le vif du sujet il y a une question à se poser …
Qui va maintenir le code ?
On a vu que ça pouvait être un membre de l’équipe, avec ou sans hache.
Mais ça peut aussi être par exemple une équipe de TMA dans une SSII, qui sous-traitera le projet à ses équipes en Inde parce que ça coûte moins cher (ndlr: obvious trolling).
Et puis ça peut être nous, dans le futur, dans six mois, dans un an, dans deux ans …

Donc les conseils que je vais donner aujourd’hui, si vous ne les appliquez pas pour les autres, faites le au moins pour vous !

Avant de parler de maintenance logicielle je voulais d’abord parler un peu de criminologie, avec ce qu’on appelle la théorie des fenêtres cassées.
Cette théorie nous explique que dans un bâtiment en bon état, si l’on casse une fenêtre et qu’on ne la répare pas, le bâtiment va avoir tendance à se dégrader de plus en plus vite.
L’idée c’est que si une première fenêtre casse et que personne ne va la réparer, personne ne va trop s’inquiéter non plus pour la deuxième. Il y en a déjà une de cassée, pourquoi réparer celle ci. De fil en aiguille, les choses vont empirer, et ça devenir normal d’avoir des fenêtres cassées un peu partout, certain·e·s n’auront même plus de scrupules à les casser volontairement.
Dans le code c’est un peu pareil. On va prendre un raccourci une fois, pour de bonnes ou de mauvaises raisons (il y a de bonnes raisons de prendre certains raccourcis). Si derrière on ne vient pas le corriger, on va avoir un problème car quelqu’un d’autre (ou soi même) va se dire que si un raccourci a été pris à un endroit, il peut être pris ailleurs. Et de fil en aiguille les malfaçons vont s’entasser pour au final créer de la dette technique.

Comme je l’ai dit, on peut avoir de bonnes ou de mauvaises raisons de créer de la dette technique, mais dans tous les cas il faut la rembourser.
Il y a plusieurs façon de la résorber. Pour moi l’un des pires ennemis de la dette technique c’est la communication.

Si vous voulez résorber la dette technique, je vous conseille vraiment de travailler sur la communication.
J’en distingue deux types : la communication entre les devs et la communication avec le reste (faute de meilleure terminologie).

La première étape de la communication entre devs, c’est d’écrire du code humain.

Qu’est ce que j’entends par “code humain” ?
Je vais reprendre cette citation de Martin Fowler, un des papas du manifeste agile, qui dit : “N’importe quel·le imbécile peut écrire du code que les machines comprennent, les bon·ne·s développeur·se·s écrivent du code que les humain·e·s comprennent”.

Il dit ça car dans notre métier on passe en moyenne 10 fois plus de temps à lire du code qu’à en écrire. Il est donc important d’écrire du code qui soit facilement lisible.
Comment faire pour écrire du code que les humains comprennent ?
Pour ça, il faut comprendre le concept de charge cognitive.
Pour faire une analogie, la charge cognitive est un peu la barrette de RAM du cerveau, c’est sa capacité de mémoire. La seule différence c’est, qu’on ne peut pas en commander sur LDLC quand on n’en a pas assez (non, j’ai pas été payé pour cette blague (ndlr: LDLC était sponsor de l’événement)).
Il y en a peut-être parmi vous qui ont des enfants en bas âge. Aujourd’hui on parle beaucoup, dans l’éducation des jeunes enfants, de charge cognitive, notamment avec les rituels. Personnellement, j’ai une petite de 2 ans qui passe en pilote automatique tous les soir à partir de l’heure du repas. Elle sait exactement quoi faire, dans quel ordre.
Les rituels sont très importants pour les enfants, certains se frustrent si on ne les suit pas. C’est simplement parce que leur cerveau est fait pour apprendre, et tout ce qui ne leur sert pas à apprendre, ce qui est trivial, que l’on fait tous les jours, c’est devenu automatique pour prendre le moins de ressources possible.
Dans le développement on peut faire la même chose, on peut essayer d’entraîner notre pilote automatique pour se focaliser sur ce qui est essentiel. Ce qui est essentiel dans le développement c’est l’algorithmie, la transformation d’un métier, d’un besoin, en code.
Il y a plusieurs façons d’optimiser cette charge cognitive. La première, assez évidente, c’est l’utilisation de standards.

Utiliser des standards, c’est écrire du code qui soit familier, et du code qui est familier c’est du code dans lequel on navigue beaucoup plus facilement et de façon automatique.
On a pas mal parlé pendant ces deux jours du PHP-FIG, qui travaille entre autres à la mise en place de standards, et on a maintenant des outils qui permettent de façon assez simple de vérifier leur respect. Si vous prenez la dernière ligne de cet exemple, elle suffit dans un serveur d’intégration continue à alerter d’un non respect des standards.
Respecter les standards c’est aujourd’hui quelque chose qui est relativement simple, les IDE le font automatiquement. Ils peuvent corriger votre code directement à la sauvegarde du fichier.
Il y a d’autres façons de limiter cette charge cognitive, par exemple avec les design patterns.

C’est finalement aussi une forme de standards. Les design patterns, dans l’idée, c’est : “à un même problème, une même solution”.
Il existe des problèmes que l’on rencontre tous les jours, que beaucoup de gens ont déjà rencontrés avant nous, et on a une solution qui est connue, qui est commune, autant l’utiliser. On ne va pas réinventer la roue à chaque fois.
En se familiarisant et en utilisant ces design patterns, on se retrouve à libérer de la charge cognitive. Les principes deviennent automatiques, on apprend à les repérer et les appliquer de façon naturelle.
Pour ceux qui ne sont pas encore trop familier avec les design patterns, je recommande ce bouquin (c’est du java, je suis désolé, mais je trouve qu’il est assez bien expliqué, il y a beaucoup d’analogies avec des cas réels et j’aime beaucoup les analogies).
Pour limiter la charge cognitive, on peut aussi faire du code qui parle comme nous …

Alors qu’est ce que j’entends par “du code qui parle comme nous” ?
En français on a une grammaire et une conjugaison. Pour autant, on peut faire des phrases qui soient justes, et que personne ne comprend, tout simplement parce qu’elles ne sont sont pas claires.
Dans le code c’est pareil, on a des syntaxes prédéfinies, mais ça ne suffit pas.
Typiquement ici, pour un article de blog on a une fonction setState qui attend une chaîne de caractères, et une fonction getState qui retourne une chaîne de caractères. C’est ce que j’appelle le doctrine-driven-design.

Il y a une chose que j’aime beaucoup faire, et qui se voit beaucoup dans les revues que je fais, c’est de transposer le code en phrases en français. Typiquement dans ce cas précis, si je veux publier mon article de blog, la phrase en français que je vais donner comme instruction à mon blog ça sera “définit l’état de l’article à publié”
Si l’on veut parler un peu plus français il faudrait tout simplement lui donner l’instruction : “Publie l’article”.

Les deux sont corrects d’un point de vue “grammaire et conjugaison du code”, mais c’est quand même un petit peu plus clair de dire “publie” et “dit moi si tu es publié”.
Écrire du code qui parle comme nous, ça libère de la charge cognitive puisqu’on ne va plus réfléchir trois heures à comprendre le code, il est relativement naturel dans sa lecture.
Le dernier point que je vais aborder sur la charge cognitive c’est la complexité cyclomatique.

La complicité cyclomatique c’est avant tout un mot assez compliqué qui va vous aider à paraitre très intelligent quand vous l’utiliserez dans une revue de code.
Sa vraie définition, c’est un index calculé sur le nombre de chemins linéairement indépendants que peut prendre un algorithme. Pour simplifier, quand vous avez un if avec une condition très simple vous augmentez votre complexité cyclomatique de 1. Vous aviez un chemin, maintenant vous en avez deux : celui qui passe dans le if et celui qui n’y passe pas.
La complexité cyclomatique c’est finalement un concept assez simple avec un nom très compliqué qui donne l’air intelligent.
Cette complexité est liée à la charge cognitive, puisqu’à chaque fois qu’on va rajouter des chemins, il va falloir les retenir lors du debug ou des modifications.
Essayer de limiter la complexité cyclomatique c’est finalement rendre le code plus maintenable.
D’ailleurs existe un outil (qui est français, cocorico), qui s’appelle phpMetrics et qui permet d’afficher différents facteurs de maintenance, notamment ces graphiques.
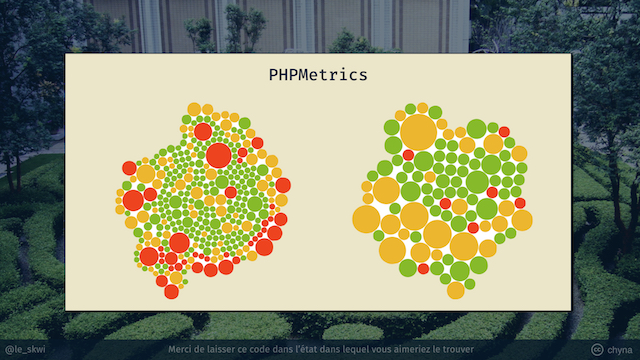
Chaque disque correspond à un fichier. La taille d’un disque correspond à la complexité cyclomatique du fichier et sa couleur à son niveau de maintenabilité, calculé avec différentes métriques exhaustives.
Sur cette image on a deux projets différents, de tailles assez différentes, mais dans les 2 cas on a une corrélation entre la complexité cyclomatique d’un fichier et sa maintenabilité. Ce ne sont jamais les gros disques qui sont qui sont les plus verts.
Voilà pour ce qui est d’écrire “du code humain”. Le prochain point, qui fâche un petit peu plus, c’est la documentation.

En général dans le développement on n’aime pas trop la documentation, sauf certains, ou certaines…
Pourtant la documentation est importante. Si vous étiez hier dans la bonne salle vous le savez. (ndlr: @sarahhaim a présenté la veille un conférence sur le sujet)
Le point d’entrée de la documentation c’est le fichier README.md.

Aujourd’hui, sur les principales plateformes de contrôle de code source, que ce soit Github, Gitlab, Bitbucket … quand vous arrivez sur un projet vous tombez sur le contenu de ce fichier README.md.
Il est là pour donner les clefs pour démarrer sur le projet.
Ça n’a pas besoin d’être une documentation exhaustive de tout ce que peut faire le code, mais ça doit donner les clés. Normalement si on suit bien tout ce qui est expliqué dans ce fichier, on est opérationnel·le, prêt·e à travailler, prêt·e à être productif·ve.
Donc essayez de faire vos README.md de façon à ce que celles et ceux qui le lisent soient immédiatement productif·ve·s sur les projets sur lesquels vous travaillez.
Le README.md c’est donc le point d’entrée. Mais ce qui fâche le plus c’est d’écrire la suite, les gros pavés de documentation. On n’aime pas le faire car de toute façon ça ne sera pas maintenu, il faudra tout réécrire à chaque fois que le projet évolue (donc tout le temps).
Heureusement, aujourd’hui on a ce que l’on appelle la documentation vivante. Comme son nom l’indique c’est une documentation qui va vivre avec le code.
Il y a plusieurs catégories de documentation vivante, la première que je vais vous présenter aujourd’hui c’est la documentation auto-invalidée.

Le type de documentation auto-invalidée que l’on rencontre le plus souvent, ce sont les tests.
Ici, je lance une suite de tests qui vérifie que mon mon post peut être publié. Le jour où je fais une modification dans le code et que mon test devient rouge, je sais que mon test de documente plus mon code, donc ma documentation n’est plus valide.

Parmi les autres types de documentation vivante, il y a la documentation auto-générée. Là c’est royal, tout va se faire tout seul… Enfin ça n’est pas aussi facile mais l’idée c’est que la documentation se génère de façon automatique.

Il y a plein d’outils pour ça, celui dont je vais parler aujourd’hui c’est Pickles. Il est très simple. Il suffit de lui passer des scénarios sous forme de features Gherkin (ce que l’on utilise dans Behat) et il va générer un petit site web pseudo-dynamique où vous allez avoir un menu, une fonction de recherche…
Si vos features Gherkin sont bien écrites et qu’elles expliquent bien le métier, vous allez générer quelque chose qui peu servir de manuel utilisateur, en html, et utilisable par n’importe qui, même non-technique.
Le dernier mode de documentation vivante dont je voulais parler aujourd’hui c’est la documentation vivante historique.

Cette documentation, c’est le contenu du contrôle de code source.
Prenons un scénario : les deux types de documentation citées précédemment ne sont pas disponibles. Vous travaillez sur un bout de code, et vous rencontrez un algo que vous ne comprenez pas très bien. Vous vous dites que vous pouvez aller voir dans le l’historique GIT pour trouver le commit qui correspond à cette modification. Il y aura peut-être des explications sur le message de commit.
Et là vous tombez sur ça :
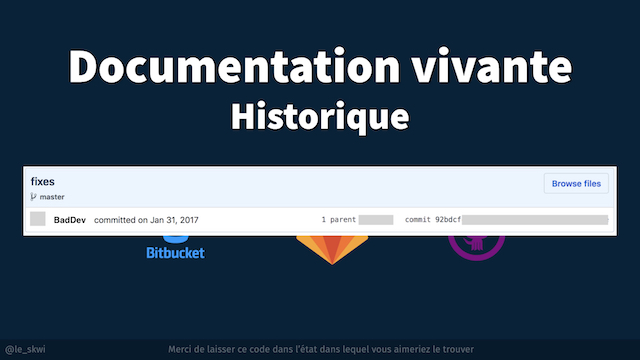
“fixes” …
Celui ci c’est mon préféré, parce que “fixes” a cette particularité d’être au pluriel. C’est à dire que potentiellement, il va y avoir des modifications dans ce commit qui ne vont pas du tout m’intéresser.
Les messages de commit c’est quelque chose de super important. C’est de la documentation, donc il faut y apporter un minimum d’attention.
Il y a un petit point sur lequel je voulais insister aussi, c’est que souvent on oublie, même en s’appliquant, de préciser le contexte du commit.
Quand on écrit ou lit un message de commit dans le contexte de la modification (le jour même, le lendemain), on sait à quoi les modifications correspondent. On oublie que six mois après, il va manquer la moitié des informations quand on reviendra sur ce message, surtout si c’est une personne différente. C’est donc une bonne habitude de préciser le contexte d’un commit.
Autre conseil que je donnerais, c’est d’expliquer le “pourquoi” du commit. Quand on va aller chercher une information dans un message de commit, c’est souvent ce que l’on veut savoir “pourquoi ?”. Il n’est pas nécessaire d’expliquer exactement ce qui a été fait, on peut le voir en lisant le code.
Dernière petite astuce, qui n’est pas très connue, c’est qu’un message de commit peut être multi-lignes.
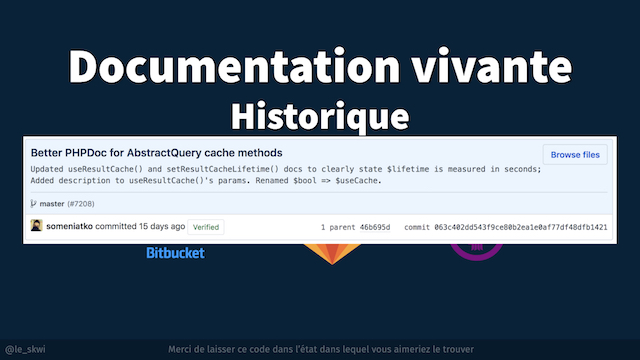
La première ligne correspond au message du commit, et toute la suite est interprétée comme une description. Même si vous n’avez pas envie de faire un message de commit trop longs, par exemple parce qu’ils ne s’affichera pas en entier sur Github, vous pouvez apporter pas mal d’informations grâce à cette description.
Le jour où quelqu’un ira voir ce commit, il pourra par exemple avoir des infos sur le contexte.
Voilà pour la partie documentation. Mon dernier point dans la communication entre développeurs c’est de faire des revues.

Par revue, j’entends beaucoup de choses. Il y a les revues de code, mais il y a aussi le pair programming, et le mob programming aussi, plus on est de fous plus on rit.
L’idée sous-jacente à la revue et toutes ces autres pratiques est qu’il n’y ai jamais une seule personne qui ai travaillé sur un bout de code. Il faut qu’il soit commun à plusieurs personnes avant de partir en production.

Si on regarde la revue avec des œillères, c’est de la perte de productivité : deux personnes travaillent sur la même chose alors que finalement une seule personne suffirait.
Mais grâce à la revue, on a de la diffusion de responsabilité, c’est à dire qu’on n’a plus une seule personne qui porte sur ses épaules la responsabilité d’un bout de code.
On a également de la diffusion de connaissances puisque tous ceux qui ont lu le code, sans forcément toujours rentrer dans les détails, ont au moins un peu de connaissance de ce qui a été fait.
La qualité s’en retrouve augmentée. Des études ont montré que la revue de code est plus efficace que les tests unitaires pour détecter des bugs ou des failles de sécurité (ce qui n’enlève pas l’intérêt des tests).
La revue de code ça n’est donc pas de la perte de temps.
On en fait depuis plusieurs années maintenant à Novaway, et c’est vraiment le truc sur lequel je ne reviendrai pas, c’est la partie la plus importante de notre process qualité.
Voilà pour la partie communication entre développeurs : écrire du code humain, le documenter en mode “code augmenté”, pas forcément en texte brut, et faire des revues.

L’autre question qui nous intéresse, c’est comment communiquer avec le reste ?
Pour bien communiquer avec les personnes non techniques, il faut comprendre le concept de feedback loop.

Si l’on regarde bien, il y a pas mal de tendances dans le développement logiciel, que ce soit Scrum, le Lean Startup … qui ont une même philosophie : réduire au maximum la feedback loop, pour avoir des retours le plus rapidement possible.
Ça vaut pour du feedback produit, mais ça vaut également pour du feedback dans une équipe ou avec un client.
Si on attend un mois pour remonter certaines informations, l’information ne sera plus pertinente. Ce qui fait la pertinence d’une information c’est aussi le moment à laquelle elle est délivrée. Plus on réduit cette feedback loop, plus on a de possibilités de donner une information qui soit pertinente d’un point de vue temporel.
Dans vos communications, essayez de réduire au maximum la feedback loop. Ça peut se faire avec les méthodes agile par exemple avec des meetings quotidiens, avec des rétrospectives en fin de sprint. L’idée c’est vraiment de communiquer le plus souvent possible, ne pas attendre trop longtemps pour remonter un problème ou une information.
Il y a peut-être des managers dans la salle… Dans mon premier emploi en tant que développeur, tous les managers avec lesquel·le·s j’ai travaillé avaient cette fameuse politique de la porte ouverte.

Cette politique c’est celle qui consiste à dire à tout le monde “Tu peux venir dans mon bureau, il n’y a pas de problème, si tu vois un truc qui ne va pas bien, tu viens me voir, ma porte est toujours ouverte.”
À l’époque j’étais junior, j’avais moins de deux ans d’expérience et en plus je suis introverti par nature … Autant vous dire que je ne suis jamais allé les voir. J’avais beaucoup de choses à dire, mais je ne suis jamais allé les voir.
Je pense que je ne suis pas le seul dans ce cas, et pour moi la politique de la porte ouverte est assez néfaste car c’est une décharge de responsabilité du ou de la manager vers les équipes qui sont managées.
Ça ne veut pas dire que les équipes n’ont aucune responsabilité dans la communication, mais ça n’est pas leur rôle de détecter ce qui ne va pas dans les process, et ça n’est pas leur rôle de mettre les choses en place pour régler les problèmes.
A titre personnel, je n’aimerai pas un jour me retrouver à la fin d’une situation de crise à dire à quelqu’un “Mais tu aurais dû venir me voir”. Si je dis ça, c’est un échec en tant que manager. C’est à moi d’aller rencontrer les gens et de savoir ce qui se passe de bien ou de pas bien.
Pour remédier à ça, assez récemment, j’ai mis en place une politique de 1-on-1.

L’idée c’est de faire des entretiens individuels avec l’équipe. Pour le moment j’essaie de le faire au moins une fois par mois, j’aimerais le faire encore plus.
Le but des 1-on-1 c’est de faire des points. Pas des points projet, il ne faut vraiment pas s’en servir pour parler avancement, il y a des outils et des process pour ça. Le 1-on-1 c’est vraiment un moment pour savoir un peu comment ça se passe pour la personne. On peut parler carrière, on peut parler conseils, on peut même parler perso, il y a plein de sujets à aborder, mais toujours autour de la personne …
L’idée c’est vraiment d’avoir ce ressenti de la part des équipes, de ne pas attendre l’entretien annuel pour savoir ce qui va ou ce qui ne va pas, parce qu’entre deux entretiens individuels, quelqu’un qui n’est pas bien a largement le temps de voir sa situation empirer et de partir.
Le but c’est que les gens se sentent bien dans leur boulot, et donc d’essayer de repérer au plus vite les soucis. Ça peut être des choses qui sont anodines, parce que même les choses anodines peuvent par effet boule de neige empirer et si on ne l’a pas repéré assez rapidement on ne peut pas mettre en place les actions correctives nécessaires.
Donc les politiques de 1-on-1, pour détecter les problèmes, pour faciliter la communication, c’est quelque chose de très utile.
Voilà la communication “avec le reste” : réduire la feedback loop, éviter d’avoir une politique de “porte ouverte” parce que ça ne marche pas, et essayer d’avoir, par exemple, des 1-on-1 (il y a peut-être d’autres méthodes que je ne connais pas, mais je trouve celle ci assez pertinente)

Je finirai cette présentation sur une citation d’une de mes idoles depuis maintenant bien longtemps : “Le talent remporte des matches mais c’est le travail d’équipe et l’intelligence qui remportent des championnats”.

Merci à vous.
Questions - réponses
Q: J’avais une question concernant la fréquence des revues de code, quelle est selon toi la meilleure fréquence ? si c’est quotidien ? si c’est hebdomadaire ? si c’est sur un exemple d’un gros contrôleur ? etc … ou si il faut à chaque contrôleur, pour chaque fonction refaire une review à chaque fois ?
R: À chaque fois. Si tu prends aujourd’hui toutes les grandes plateformes de contrôle de code source, que ce soit Github, Gitlab, Bitbucket … elles fonctionnent toutes sur un système de Merge Request ou Pull Request qui permet de réintégrer un développement dans le tronc commun.
À chaque fois que tu as cette réintégration dans le tronc commun, tu dois passer par une revue de code pour dire “OK c’est bon” ou “Non il y a ça, ça, et ça qui va pas”.
La bonne pratique c’est d’essayer de faire du travail le plus découpé possible, parce qu’il y a un dicton qui dit “on va passer une heure sur une revue de 10 lignes de code, et 10 minutes sur une revue de 200 lignes de code”. Les gens seront plus attentifs à ce que tu as fait si c’est assez atomique alors que si tu balances un gros pavé, les gens vont le lire en diagonale et au final ça va potentiellement passer avec des problèmes.
L’idée c’est vraiment de se dire que dès qu’il y a quelque chose qui réintègre le tronc commun, c’est revu, ça ne passe pas en prod si ça n’a pas été pas revu.
Q: Ma question c’était sur le 1-on-1. J’en ai fait à une période mais il est vrai qu’il ya certaines choses, même en 1-to-1 que je ne disais pas parce que j’étais potentiellement intimidé, ou je ne voulais pas que ça me retombe dessus derrière, ou autre … du coup qu’est ce que tu conseillerai comme dialogue, comme message pour mettre la personne en confiance et qu’elle soit honnête envers toi même ?
R: Alors j’avoue que je n’ai pas de recette magique. Ça peut paraître bateau mais mon conseil serait de s’intéresser à la personne de façon sincère. Il ne faut pas se dire “Je fais ce 1-on-1 parce que c’est le process de faire des 1-on-1, ça me fait chier d’être là mais je le fais avec cette personne”. Non il faut être sincèrement intéressé par la personne avec qui tu travailles.
Je pense que si tu n’es pas intéressé par les personnes avec qui tu travailles, tu n’as pas vraiment ta place en tant que manager.
Manager ça n’est pas un échelon, ça n’est pas une évolution du développeur, c’est un autre métier. Et si tu n’es pas intéressé par l’humain, par les gens avec qui tu évolue, ça n’est pas pour toi le boulot de manager.
Être sincèrement intéressé c’est la meilleure façon de mettre les gens en confiance. Je ne dis pas que ça marche à chaque fois, mais au moins tu auras la démarche pour le faire de façon naturelle.